In this article we will look at the role of BigData and Data Analytics in IoT. First we will define what is BigData then have a look at different applications of BigData and finally list out different Data Analytics tools.
Disclaimer: The content in this article was copied from the content available on intellipaat.com. The sole purpose of doing this is to make it easily available for students who are studying IoT in their curriculum.
Contents
Introduction
Data can be defined as the figures or facts which can be stored in or can be used by a computer. Big Data is a term that is used for denoting the collection of datasets that are large and complex, making it very difficult to process using legacy data processing applications. BigData is characterized by 5Vs as shown below.
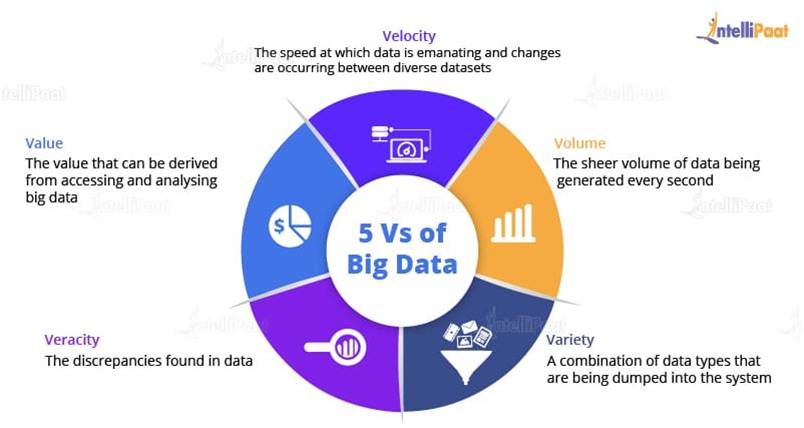
Volume: This refers to the data that is tremendously large. As you can see from the image, the volume of data is rising exponentially. In 2016, the data created was only 8 ZB and it is expected that, by 2020, the data would rise up to 40 ZB, which is extremely large.
Variety: A reason for this rapid growth of data volume is that the data is coming from different sources in various formats. The data is categorized as follows:
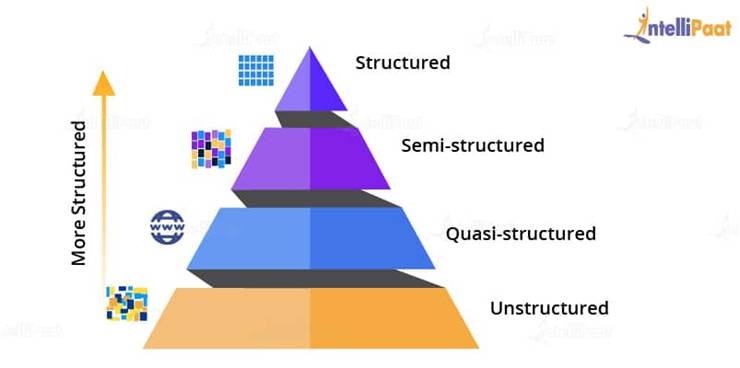
- Structured Data: Here, data is present in a structured schema, along with all the required columns. It is in a structured or tabular format. Data that is stored in a relational database management system is an example of structured data. For example, in the below-given employee table, which is present in a database, the data is in a structured format.
- Semi-structured Data: In this form of data, the schema is not properly defined, i.e., both forms of data is present. So, basically semi-structured data has a structured form but it isn’t defined, e.g., JSON, XML, CSV, TSV, and email. The web application data that is unstructured contains transaction history files, log files, etc. OLTP systems (Online Transaction Processing) are built to work with structured data and the data is stored in relations, i.e., tables.
- Unstructured Data: In this data format, all the unstructured files such as video files, log files, audio files, and image files are included. Any data which has an unfamiliar model or structure is categorized as unstructured data. Since the size is large, unstructured data possesses various challenges in terms of processing for deriving value out of it. An example for this is a complex data source that contains a blend of text files, videos, and images. Several organizations have a lot of data available with them but these organizations don’t know how to derive value out of it since the data is in its raw form.
- Quasi-structured Data: This data format consists of textual data with inconsistent data formats that can be formatted with effort and time, and with the help of several tools. For example, web server logs, i.e., a log file that is automatically created and maintained by some server which contains a list of activities.
Velocity: The speed of data accumulation also plays a role in determining whether the data is categorized into big data or normal data. As can be seen from the image below, at first, mainframes were used wherein fewer people used computers. Then came the client/server model and more and more computers were evolved.
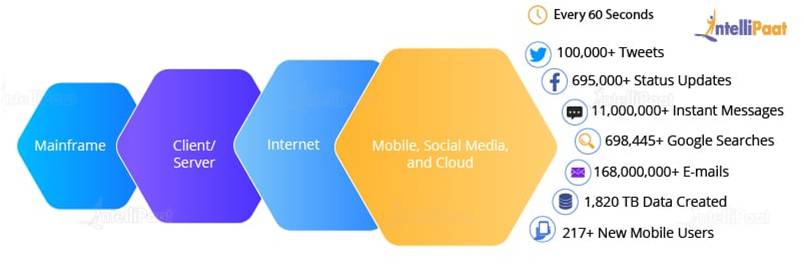
After this, the web applications came into the picture and started increasing over the Internet. Then, everyone began using these applications. These applications were then used by more and more devices such as mobiles as they were very easy to access. Hence, a lot of data. As it is clear from the image below, every 60 seconds, so much of the data is generated.
Value: How will the extraction of data work? Here, our fourth V comes in, which deals with a mechanism to bring out the correct meaning out of data. First of all, you need to mine the data, i.e., a process to turn raw data into useful data. Then, an analysis is done on the data that you have cleaned or retrieved out of the raw data.
Then, you need to make sure whatever analysis you have done benefits your business such as in finding out insights, results, etc. which were not possible earlier. You need to make sure that whatever raw data you are given, you have cleaned it to be used for deriving business insights. After you have cleaned the data, a challenge pops up, i.e., during the process of dumping a huge amount of data, some packages might have lost. So for resolving this issue, our next V comes into the picture.
Veracity: Since the packages get lost during the execution, we need to start again from the stage of mining raw data in order to convert them into valuable data. And this process goes on. Also, there will be uncertainties and inconsistencies in the data. To overcome this, our last V comes into place, i.e., Veracity.
Veracity means the trustworthiness and quality of data. It is necessary that the veracity of the data is maintained. For example, think about Facebook posts, with hashtags, abbreviations, images, videos, etc., which make them unreliable and hamper the quality of their content. Collecting loads and loads of data is of no use if the quality and trustworthiness of the data is not up to the mark.
BigData Applications
Banking
Since there is a massive amount of data that is gushing in from innumerable sources, banks need to find uncommon and unconventional ways in order to manage big data. It’s also essential to examine customer requirements, render services according to their specifications, and reduce risks while sustaining regulatory compliance. Financial institutions have to deal with Big Data Analytics in order to solve this problem.
Government
Government agencies utilize Big Data and have devised a lot of running agencies, managing utilities, dealing with traffic jams, or limiting the effects of crime. However, apart from its benefits in Big Data, the government also addresses the concerns of transparency and privacy.
Education
Education concerning Big Data produces a vital impact on students, school systems, and curriculums. With interpreting big data, people can ensure students’ growth, identify at-risk students, and achieve an improvised system for the evaluation and assistance of principals and teachers.
Healthcare
When it comes to what Big Data is in Healthcare, we can see that it is being used enormously. It includes collecting data, analyzing it, leveraging it for customers. Also, patients’ clinical data is too complex to be solved or understood by traditional systems. Since big data is processed by Machine Learning algorithms and Data Scientists, tackling such huge data becomes manageable.
e-Commerce
Maintaining customer relationships is the most important in the e-commerce industry. E-commerce websites have different marketing ideas to retail their merchandise to their customers, to manage transactions, and to implement better tactics of using innovative ideas with Big Data to improve businesses.
Social Media
Social media in the current scenario is considered as the largest data generator. The stats have shown that around 500+ terabytes of new data get generated into the databases of social media every day, particularly in the case of Facebook.
The data generated mainly consist of videos, photos, message exchanges, etc. A single activity on any social media site generates a lot of data which is again stored and gets processed whenever required. Since the data stored is in terabytes, it would take a lot of time for processing if it is done by our legacy systems. Big Data is a solution to this problem.
BigData Analytics
Big Data Analytics examines large and different types of data in order to uncover the hidden patterns, insights, and correlations. Basically, Big Data Analytics is helping large companies facilitate their growth and development. And it majorly includes applying various data mining algorithms on a certain dataset.
Big Data Analytics is used in a number of industries to allow organizations and companies to make better decisions, as well as verify and disprove existing theories or models. The focus of Data Analytics lies in inference, which is the process of deriving conclusions that are solely based on what the researcher already knows.
Tools for BigData Analytics
Apache Hadoop: It is a framework that allows you to store big data in a distributed environment for parallel processing.
Apache Pig: It is a platform that is used for analyzing large datasets by representing them as data flows. Pig is basically designed in order to provide an abstraction over MapReduce which reduces the complexities of writing a MapReduce program.
Apache HBase: It is a multidimensional, distributed, open-source, and NoSQL database written in Java. It runs on top of HDFS providing Bigtable-like capabilities for Hadoop.
Apache Spark: It is an open-source general-purpose cluster-computing framework. It provides an interface for programming all clusters with implicit data parallelism and fault tolerance.
Talend: It is an open-source data integration platform. It provides many services for enterprise application integration, data integration, data management, cloud storage, data quality, and Big Data.
Splunk: It is an American company that produces software for monitoring, searching, and analyzing machine-generated data using a Web-style interface.
Apache Hive: It is a data warehouse system developed on top of Hadoop and is used for interpreting structured and semi-structured data.
Kafka: It is a distributed messaging system that was initially developed at LinkedIn and later became part of the Apache project. Kafka is agile, fast, scalable, and distributed by design.

Suryateja Pericherla, at present is a Research Scholar (full-time Ph.D.) in the Dept. of Computer Science & Systems Engineering at Andhra University, Visakhapatnam. Previously worked as an Associate Professor in the Dept. of CSE at Vishnu Institute of Technology, India.
He has 11+ years of teaching experience and is an individual researcher whose research interests are Cloud Computing, Internet of Things, Computer Security, Network Security and Blockchain.
He is a member of professional societies like IEEE, ACM, CSI and ISCA. He published several research papers which are indexed by SCIE, WoS, Scopus, Springer and others.
Leave a Reply