In this article we will look at the role of Apache Spark in IoT. First we will see an introduction to Apache Spark followed by Spark features and Spark components.
Disclaimer: The content in this article was copied from the content available on intellipaat.com. The sole purpose of doing this is to make it easily available for students who are studying IoT in their curriculum.
Apache Spark is an open-source distributed cluster-computing framework. Spark is a data processing engine developed to provide faster and easy-to-use analytics than Hadoop MapReduce. Before Apache Software Foundation took possession of Spark, it was under the control of University of California, Berkeley’s AMP Lab.
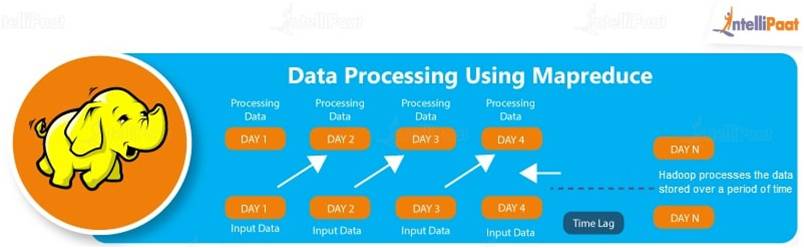
Although it is known that Hadoop is the most powerful tool of Big Data, there are various drawbacks for Hadoop. Some of them are:
- Low Processing Speed: In Hadoop, the MapReduce algorithm, which is a parallel and distributed algorithm, processes really large datasets. These are the tasks need to be performed here:
- Map: Map takes some amount of data as input and converts it into another set of data, which again is divided into key/value pairs.
- Reduce: The output of the Map task is fed into Reduce as input. In the Reduce task, as the name suggests, those key/value pairs are combined into a smaller set of tuples. The Reduce task is always done after Mapping.
- Batch Processing: Hadoop deploys batch processing, which is collecting data and then processing it in bulk later. Although batch processing is efficient for processing high volumes of data, it does not process streamed data. Because of this, the performance is lower.
- No Data Pipelining: Hadoop does not support data pipelining (i.e., a sequence of stages where the previous stage’s output ID is the next stage’s input).
- Not Easy to Use: MapReduce developers need to write their own code for each and every operation, which makes it really difficult to work with. And also, MapReduce has no interactive mode.
- Latency: In Hadoop, the MapReduce framework is slower, since it supports different formats, structures, and huge volumes of data.
- Lengthy Line of Code: Since Hadoop is written in Java, the code is lengthy. And, this takes more time to execute the program.
Having outlined all these drawbacks of Hadoop, it is clear that there was a scope for improvement, which is why Spark was introduced. Spark provides:
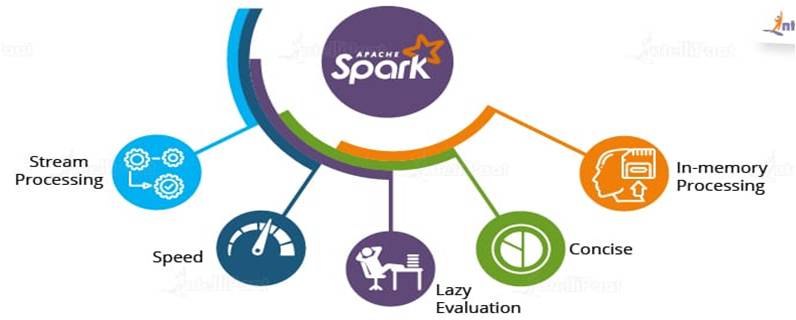
- In-memory Processing: In-memory processing is faster when compared to Hadoop, as there is no time spent in moving data/processes in and out of the disk. Spark is 100 times faster than MapReduce as everything is done here in memory.
- Stream Processing: Apache Spark supports stream processing, which involves continuous input and output of data. Stream processing is also called real-time processing.
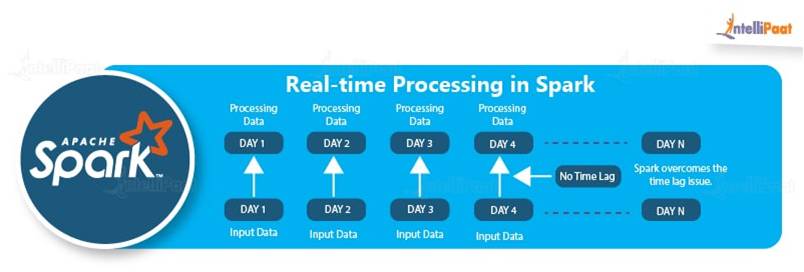
- Less Latency: Apache Spark is relatively faster than Hadoop, since it caches most of the input data in memory by the Resilient Distributed Dataset (RDD). RDD manages distributed processing of data and the transformation of that data. This is where Spark does most of the operations such as transformation and managing the data. Each dataset in an RDD is partitioned into logical portions, which can then be computed on different nodes of a cluster.
- Lazy Evaluation: Apache Spark starts evaluating only when it is absolutely needed. This plays an important role in contributing to its speed.
- Less Lines of Code: Although Spark is written in both Scala and Java, the implementation is in Scala, so the number of lines are relatively lesser in Spark when compared to Hadoop.
Spark Components
Spark as a whole consists of various libraries, APIs, databases, etc. The main components of Apache Spark are as follows:
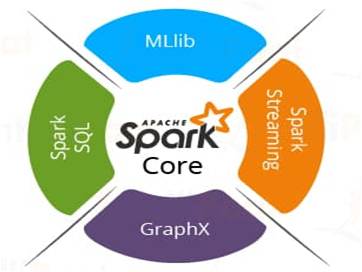
Spark Core: It is the basic building block of Spark, which includes all components for job scheduling, performing various memory operations, fault tolerance, and more. Spark Core is also home to the API that consists of RDD. Moreover, Spark Core provides APIs for building and manipulating data in RDD.
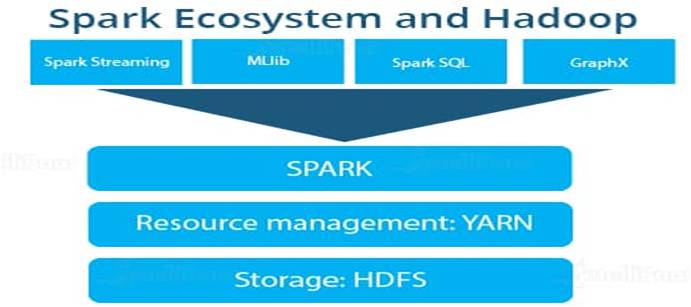
Spark SQL: It works with the unstructured data using its ‘go to’ tool, Spark SQL. Spark SQL allows querying data via SQL, as well as via Apache Hive’s form of SQL called Hive Query Language (HQL). It also supports data from various sources like parse tables, log files, JSON, etc. Spark SQL allows programmers to combine SQL queries with programmable changes or manipulations supported by RDD in Python, Java, Scala, and R.
Spark Streaming: It processes live streams of data. Data generated by various sources is processed at the very instant by Spark Streaming. Examples of this data include log files, messages containing status updates posted by users, etc.
GraphX: It is Apache Spark’s library for enhancing graphs and enabling graph-parallel computation. Apache Spark includes a number of graph algorithms which help users in simplifying graph analytics.
MLlib: It comes up with a library containing common Machine Learning (ML) services called MLlib. It provides various types of ML algorithms including regression, clustering, and classification, which can perform various operations on data to get meaningful insights out of it.
Hadoop and Spark Together
There are some scenarios where Hadoop and Spark go hand in hand.
- Spark can run on Hadoop, stand-alone Mesos, or in the Cloud.
- Spark’s MLlib components provide capabilities that are not easily achieved by Hadoop’s MapReduce. By using these components, Machine Learning algorithms can be executed faster inside the memory.
- Spark does not have its own distributed file system. By combining Spark with Hadoop, you can make use of various Hadoop capabilities. For example, resources are managed via YARN Resource Manager. You can integrate Hadoop with Spark to perform Cluster Administration and Data Management.
- Hadoop provides enhanced security, which is a critical component for production workloads. Spark workloads can be deployed on available resources anywhere in a cluster, without manually allocating and tracking individual tasks.

Suryateja Pericherla, at present is a Research Scholar (full-time Ph.D.) in the Dept. of Computer Science & Systems Engineering at Andhra University, Visakhapatnam. Previously worked as an Associate Professor in the Dept. of CSE at Vishnu Institute of Technology, India.
He has 11+ years of teaching experience and is an individual researcher whose research interests are Cloud Computing, Internet of Things, Computer Security, Network Security and Blockchain.
He is a member of professional societies like IEEE, ACM, CSI and ISCA. He published several research papers which are indexed by SCIE, WoS, Scopus, Springer and others.
Leave a Reply